Risk Management: Challenges and Guidelines
Table of Contents
1. Lecture 9
- Class: Security Governance
- Topic: Risk Management
There are different challenges in the cyber-risk management. The first thing to consider is which measure of risk level to use, depending on the cyber risks considered can be useful to use a particular model or measure. The second question is What scales are best suited under what conditions?; the definition of the scale has to be done in the first part of the Context Establishment, it is an a priori activity. For this reason being aware of different options can be useful to take good decision in this phase. When we estimate the risk, we estimate the likelihood and impact of it, so it is fundamental to reduce the uncertainty, avoiding the need to iterating the assessment part of each risk. At least there are some kind of risks that are characterized with a very low likelihood but high impact, this risks are serious for the company but their treatment can be very expensive.
2. Which Measure of Risk Level to use.
The risk is simply a function that depends on likelihood and consequences (impact). The two variables can be measured independently using a classical two-factor measure of risk:
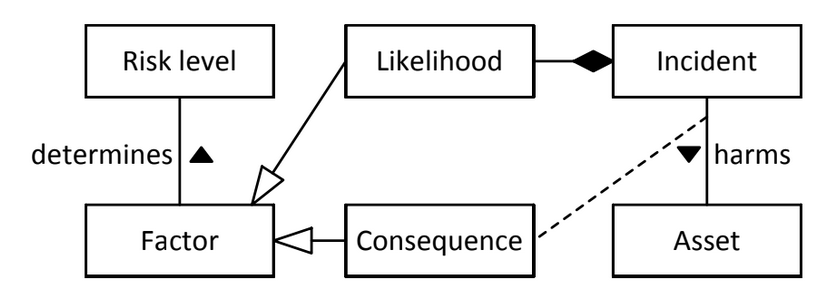
- The consequence depend on a relationship between the Incident and the Asset,
- The likelihood depends only on the Incident without considering the Asset. The Incident can be considered as an high level abstraction that aggregate the threat and the threat source together with the Incident itself. When low level information is present, when some assessing some type of risks, like misbehavior of employees, this kind of model is perfect.
2.1. Three Factor Measure
NIACAP defines risk as:
A combination of the likelihood that a threat will occur, the likelihood that a threat occurrence will result in an adverse impact and the severity of the resulting impact.
So we decompose the computation in: the likelihood that a threat will occur and the likelihood that a threat will become and incident. This model result in more advanced sophisticated statistical analysis.
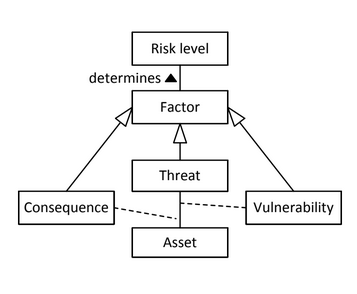
Now likelihood is decomposed in two parts: evaluation of the threat and evaluation of the vulnerability, the threat is directly linked to the asset, where the vulnerability is linked to the relation between threat and asset. So the vulnerability as to be related to an asset and enable a threat. The consequences is also related to both the asset and the threat; because the asset itself does not tell anything about the impact.
In a situation in which there are detailed information about the vulnerabilities this model will fit better and will provide additional information to be used in the risk mitigation phase. It is particularly useful when doing risk estimation of an IT infrastructure:
- Very detailed information that can be acquired via vulnerability scanners;
- Use repositories to identify attack patterns and related threats;
- Acquire information about possible related threats and likelihood
When reasoning at the network level this model will produce a refined low level analysis.
2.2. Many Factor Measure
It is a generalization of the Three factor measure in which also the consequences are split in technical-consequences and business-consequences. For example an asset can be important at the technical level but insignificant at the business level. In general we can add as many variables as we want:
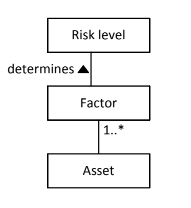
An high number of factor represent an higher level of detail, but a lot of high quality data is needed, otherwise if a high quantity of low quality data can lead to high uncertainty.
2.3. Considerations
Which approach you should use and how you should use it depends on the context and your risk assessment situation
Every measure will depends on the type of analysis and on the environment in which we are working. For example in the network level we need much fine granularity; at the other hand at the strategic level an aggregation has to be performed to provide an high level overview of the risk. The aspects to consider when choosing a measurement model are:
- The availability of data and its quality: if from the environment we can extract only qualitative information then we can’t use a quantitative method. Trade off between level, quality and measurability of data.
- If it is possible to extract information directly regarded to the incident force the selection of a model. The selection of the model is not independent from the type of data.
- In the cybersecurity domain the multi factor measure is very used because the public repositories a lot of information are provided.
- Most of the time the problem is not the lack of data, but the lack of the right kind of data needed by the model used. The Communication and Consultation phase is important to declare which information are important to gather and measure. This situations arise because most of the time we rely on default logging configuration, that produce a lot of data that most of the time can be noisy or lacking of useful feature. Reasoning on the tye of information needed is fundamental to increase the accuracy.
- A different approach consist on starting from the data instead that from the model. Of course this activity as to be performed carefully, if the processes are unknown it is easy to underestimate/overestimate some aspects of the processes. Data Mining and Machine Learning techniques can be used.
- If some information are provided by stakeholders it is important to consider that the data gathered can have different level of granularity and quality; so the information is not structured or detailed. It is important to use less factors if much of the information is provided by stakeholders.
- It is crucial to use the right scale to represent each variable; the scale has to be appropriate to capture the important information.
Once the model is fixed, for each variable we need to define how to quantify it.
3. What scales are best suited, and under what conditions?
The suitability of a particular scale depends on different points:
- The factor in question. For example is we want to quantify a likelihood we can consider the frequencies to estimate the possibility of an event to occur taking into consideration historical data.
- The kind of risk under evaluation. If we are on the technical level, higher precision is needed, so numerical scales can be used. In higher levels, for example when considering loss of reputation, a discrete scale may be used.
- The target of assessment. In a technical assessment we’ll use some kinds of scale, at higher levels aggregate scales are used: green, yellow and red scale for example.
- The available source data. It is useless to define a quantitative scale if all the data gathered is qualitative.
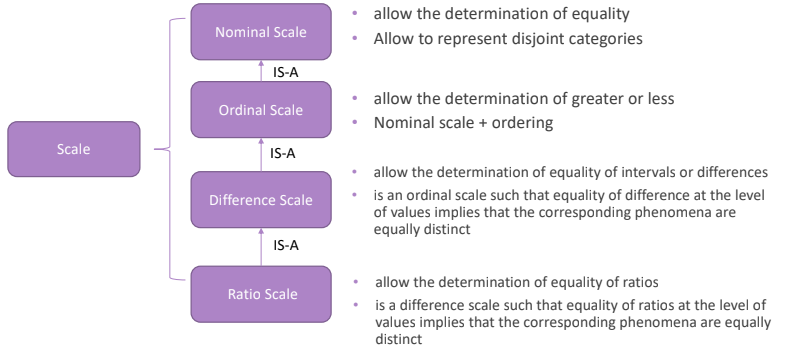
There exists different kinds of scale:
- Nominal scale. Allow the determination of equality, and its used to make classification of elements; it is not possible to compare elements in different groups.
- Ordinal scale. It is a nominal scale that include an order between elements in different groups; for example low, medium and high categories.
- Difference scale. Allows to work with inequalities, so ordering quantities reasoning over intervals. Measurement are based on the delta.
- Ratio scale. This case allow the ordering, but it is used to represent a proportion: “the number of identity thefts in Europe in a Year”.
The first two are qualitative, the last two are quantitative. We’ll focus on the second and the fourth because they are the most used.
3.1. Differences between Qualitative and Quantitative
| Quantitative | Qualitative |
|---|---|
| Information that need to be quantifies are homogeneous, tends to work better at a technical level, and requires a fine level of granularity | Information that need to be quantified are not homogeneous. In the same class can be heterogeneous elements introducing some imprecision |
| Easy to pass from quantitative to qualitative | Difficult to convert qualitative scale to quantitative data. |
| It easy in theory, but it is not necessarily practical; numbers do not always capture the meaning of a measurement. | A purely qualitative approach is not satisfactory on its own. Comparing something in the same class is difficult and not always viable: how can we prioritize the elements inside the Medium class? |
3.2. Scales for likelihood.
The likelihood is a measure of the probability of the occurrence of an incident. If we use a numerical scale is important to consider that there is an uncertainty aspect. Another thing to consider is the fact that sometimes historical data is present, so the scale has to capture also them; if historical data is not present a quantitative scale may be not usable. The third element to consider is the fact that if we use a quantitative scale that does not fit with the situation that we want to represent can lead to huge errors, leading to bias.
It is not recommended to use quantitative scales when the information comes from people. It is better to look for intervals of frequencies or qualitative scales instead that using absolute frequencies.
3.3. Scales for consequences.
A risk evaluation may end up with a cost-benefit analysis, so depending on the asset there may be very different characteristics to consider.
- For some assets we can have a 1:1 proportion between the incident and the monetary value of the asset. If a bag of diamond is stolen then the cost consequence of the incident is equal to the cost of the diamonds.
- For other assets, there is not a 1:1 proportion. When talking about the integrity of a database, can be easy to characterize the number of records affected, but hard to say what is the cost of each record affected.
- Some assets do not have any quantitative scale, like the reputation.
The scale depends on the asset; so a general scale can’t be defined; so it is recommended to define a consequence scale for each asset of relevance, so each scale has to fits its intended usage. On the strategic level the risk is better to be quantified in money terms, on the technical level is better to quantify information on the practical level.
NOTE: The suitability of a consequence scale depends on the asset in question
3.4. What scale to use for cyber risk.
In the cyber scale, there is a complication that comes from the fact that when dealing with the ICT part the impact of an incident at the technical level can be quite different from the impact at the strategic level.
4. How to deal with uncertainty.
The ISO 31000 defines uncertainty to be:
The state, even partial, of deficiency of information related to, understanding or knowledge of an event, its consequence, or likelihood.
There are two type of uncertainty: epistemic and aleatory.
4.1. Epistemic uncertainty.
It is due to the lack of information, clean data, or right data. In case of perfect knowledge there is no epistemic uncertainty, and there is no further knowledge to be gained from additional empirical investigations. In case of imperfect knowledge there is always some epistemic uncertainty.
4.2. Aleatory Uncertainty.
Comes from inherent randomness in some processes.
4.3. How we can represent Uncertainty
Quantitative scales can be used, maybe representing uncertainty by using intervals, where the width of the interval represent the level of uncertainty. This reflects on the representation of a risk in the risk matrix not in a well defined cell but as an area in the matrix which depend on the level of uncertainty:
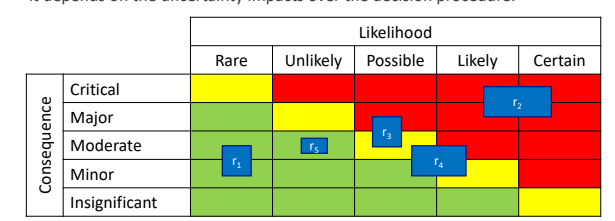
The level of acceptable uncertainty depends on its impact over the decision procedure. To deal with this aspect a qualitative can be used, it gives an overview of mistakes done during the evaluation, for example it can be expressed as a separate natural language expression for each measurement in accordance to an ordinal scale, like: some, none and considerable to express uncertainty. Sometimes the same level of consequence without considering the uncertainty can give a bad perception of the risk.

4.4. How to reduce uncertainty.
Different methods can be used:
- Fuzzy logic
- Iterating data collection
- Comparative Analysis
- Test the risk model against historical data. If the model behaves correctly then, the model is validated also if the level of uncertainty is high, otherwise the model as to be changed to work with less factors.
5. Black Swan
It is an incident that is extremely rare and unexpected but has very significant consequences.
They are not likely to be discovered by risk assessment, and if discovered they are accepted or shared with insurances.
6. Gray Swan
It is an incident which has far-reaching consequences, but, unlike black swan can be anticipated to a certain degree.
They are caused by a degree of uncertainty, and they may be overlooked; so it is important to communicate them by increasing the level of awareness to reduce their likelihood.