Cyber-Risk Management
Table of Contents
- 1. Lecture 7
- 2. Cyber Systems
- 3. Main Challenges of Cyber-Risk Management
- 3.1. Communication and Consultation in Cyber Risk Management
- 3.2. Cyber risk Assessment in Cyber-Risk Management
- 3.3. Monitoring and Review
- 4. Common Repositories
- 5. Vulnerability Classification NVD
1. Lecture 7
- Class: Security Governance
- Topic: Cyber Risk Management
- References:NVD, CWE, CAPEC
2. Cyber Systems
When dealing with cyber space, there are some caveat to consider in the assessment part of the risk management. When performing risk identification we can have three elements, without which can be no risk: Asset, Vulnerability and Threat.
The cyber space is a collection of interconnected computerized networks, including services, computer systems, embedded processors, and controllers, as well as information in storage or transit. A cyber-system is a system that runs on top of the cyber space. A particular subset of cyber system is the cyber-physical system in which IT elements controls directly physical devices via actuators and sensors; cyber physical system are fundamental in everyday life: smart grid, smart city, healthcare and more.
Once the context is defined we can define cybersecurity: it is the set of actions to be put in place to avoid that a risk will cause harm. A cyber threat is a threat that exploits the cyberspace, it can be malicious (intentional), or non-malicious (non intentional or accidental). They have to be treated differently, in on case there is an external actor which has an objective and an intent, so the analysis is focused on the threat source and on what it will cause. In the second case, it could be for example, a crash due to a programming error, or loss of internet connection; the analysis will carried out in a completely different way, because there is no intention, so the analysis start from the problems that can arise and go to their root.
2.1. Cyber Security and Information Security
Cybersecurity is the set of activities that try to protect the assets from cyber threats, so when dealing with cybersecurity we are focused to everything that interact with the cyberspace. While information security is the protection of the information itself, so preserving the CIA properties. There is an intersection between IS and Cybersecurity, but there can be some elements that deals with one but not the other. For example there may be some information that must be protected, but their threats do not come from the cyber space (It belongs to the IS area, but it not belongs to the cybersecurity area). Most probably in few years information security will be almost completely contained in cybersecurity.
2.2. Cyber Security and Critical Infrastructure Protection
It is important to differentiate information security and critical infrastructure protection. Critical Infrastructures are infrastructures that provide basics services to the community: grid, water, transportation, finance. Today many of the CIP are provided or supported via ICT infrastructures, so there is always a step toward the digitalization that will introduce vulnerabilities. The subset of CIP that regards information protection is the CIIP (Critical Information Infrastructure Protection), it deals with the prevention of the disruption, disabling, destruction or malicious control of infrastructure. There are parts of CIIP that belong to both Cybersecurity and IS, parts that belong only to the IS, and others that are related to cybersecurity, and lastly there are also aspects that are outside of IS and Cybersecurity.
The main difficult tasks are those that belongs to Information Security, Cyber Security and CIIP.
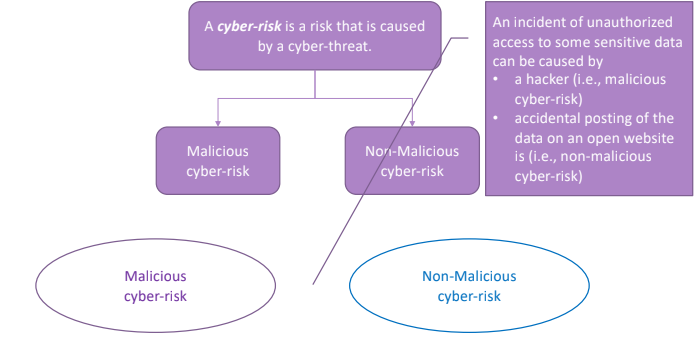
2.3. Cyber Risk
The cyber risk is basically a risk that is caused by a cyber threat. Given that we have two types of cyber threats, we can classify the cyber risk in malicious and non-malicious cyber risk. But the same kind of risk can be classified differently depending in the threat that we are going to analyze.
3. Main Challenges of Cyber-Risk Management
As we said, Risk Management it is composed by three main sub processes:Communication and Consultation , Risk Assessment and Monitoring and Review
3.1. Communication and Consultation in Cyber Risk Management
When dealing with cyber systems, additional challenges arise. The problems comes from the fact that, given that the cyberspace has no boundaries there may be infinite stakeholders. So it is impossible to consult all of them. It is important to identify the right stakeholders that can give the right estimation, given the fact that in the cyberspace may there been adversaries every were.
An help, comes from repositories of up-to-date information, for example they can come from a National CERT (Computer Emergency Response Team) or a SOC, that will act as a proxy for a stakeholders. Repositories also stores information about cyber-threats, vulnerabilities and incidents, potential and confirmed adversary profile. An important example is represented by the NIST ndv repository.
All these information helps to gather knowledge from publicly available sources used to deals with cyber-risk management.
3.2. Cyber risk Assessment in Cyber-Risk Management
In cyberspace threats can be possible spread globally, and the number of threats sources and threats, both malicious and non, can be very huge. The first main difference from the general Risk Identification is that we have to differentiate the identification of malicious cyber risk, from the identification of non-malicious risks. When We are identifying malicious risks, we have to play together the role of the attacker and of the defender; the challenge is due to the fact that there is no perfect knowledge of the resources, motivations and strategy of the attacker.
3.2.1. Context Establishment
The first main issue is to identify the internal context and the external one. Trying to understand the boundaries of the system that we want to protect is difficult, so it is fundamental to identify the possible attack surface.
The attack surface is all of the different points where an attacker or other threat source could get into the cyber-system, and where information or data can get out.
In simple terms the attack surface is composed by all the points in which the internal network interact with the internet. An example can be represented by the terminal in the intranet that can be accessed by un-trained employees. Typical assets of concern in the setting of cyber-risk identification assessment are: information and information infrastructures including software, services, network, communication facilities and machines. The processes that manages, store and process data have to be considered as assets, they are digital assets and are a fundamental part of their digital infrastructure.
3.2.2. Malicious Risk Identification
We have to differentiate malicious from non-malicious risks. When identifying malicious cyber risks we have to consider all the possible moves that an attacker can put in place to perform an attack and evade defense mechanism. The Risk assessor in some sense should try to forecast all the possible strategies of attack and defense, and suggest the defender how to play. Of course the Risk Assessor do not know about the attacker, so he has to impersonate the attacker and try to understand his motives, abilities, helpers and resources.
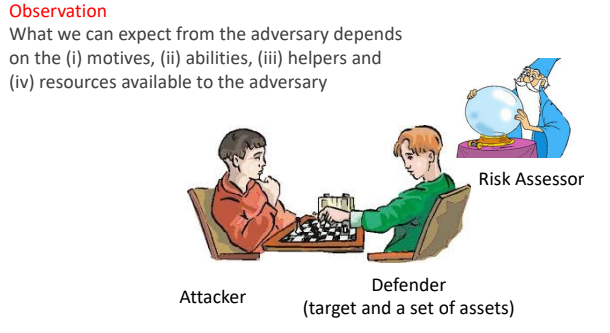
These four variables can help the Risk Assessor to perform a better risk identification, because not all the attackers are equal, so some attack can be performed only with enough resources/motivation or helpers.
This complex situation can be solved performing some steps. The input is the set of asset and target descriptions, and the output is a Risk Model.
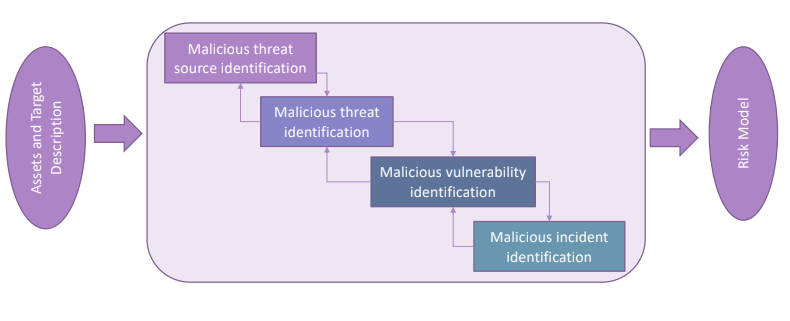
3.2.2.1. Malicious threat source identification
When we start identifying the threat source, we have to clarify: who may want to initiate the attack: if there is an agent that as an intelligence that can adapt and response to the defensive mechanisms or if the attacker is a software, that has a pre-defined behavior. Just this first step will give important information. The second step is to understand the possible motivation that lead to the attack; ant attacker with financial motivation will try to compromise particular assets. Another important aspect to consider is to state capabilities and intention of the attacker, and how and from where attacks can be launched, starting from the points defined in the attack surface, considering also the fact that the attacker may be already inside of the company network.
3.2.2.2. Malicious threat identification
We need to identify the strategy and the type of threat that the attacker may want to materialize. Given the fact that the cyberspace is huge, there are multiple kinds of threats that the attacker wants to actuate. For this reason the first step is to consult public available data, and use it to perform activities to perform target assessment, investigating where and how the attack can be launched. Some example of public repositories are those provided by MITRE, OWASP and NIST.
- Analyze the system from the inside
- Analyze the system from the outside using public repositories.
3.2.2.3. Malicious Vulnerability Identification
In this phase we focus on the identified attack surface. The first places in which we have to look for vulnerability are the points identified in the attack surface, so perform a vulnerability assessment of those points; considering:
- Software vulnerabilities
- Human vulnerabilities, and
- vulnerabilities in the processes.
This step can be performed by running: security testing like penetration testing and vulnerability scanning. Those activities are necessary to check whether or how easily a specific threat source can actually launch an attack, investigate the severity of known vulnerabilities, and looking for incidents happened to external companies.
3.2.2.4. Malicious incident identification
Investigate how a threat source can cause harm to the identifies assets given the identified vulnerabilities. Different models can be used, but still, help and guidance comes from data. It is fundamental to analyze the logs of the incident happened in the past in your or similar organization, to identify how they happened and if the same situation can reoccur; but performing historical analysis is not enough, acquisition of additional data about incidents can be gathered performing penetration testing activities. Public repositories that can be used in this phase are those produced by the National CERTs that contain forensics investigations and mitigation activities.
3.2.3. Non-Malicious Risk identification
In this case there is no particular actor that we identify, all the incident are coming from an accidental event, so the same steps used for the previous phase can’t be used. In this case, instead of starting from the threat source, we start considering the assets to be defended.
The first action to perform, after the assets identification, is to reason on which are the possible incidents that can harm an asset. So The first question to ask is: In which way the considered asset may be directly harmed?; once we identify the incident we can try to understand how and why it can be possible. So instead of going from the threats, the vulnerability, and the incident; here we start from the incident going to the possible threat sources.
Most of the time they can be environmental threat sources, or mistake in the process. The activities are the same as before, but are considered in different order:
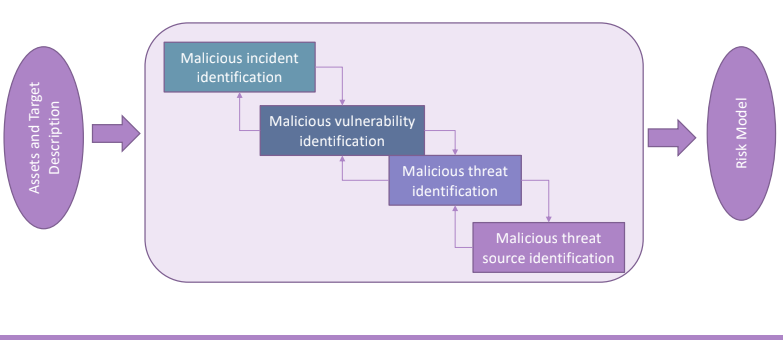
3.2.3.1. Non-Malicious Incident Identification
This activity is related to the specific kind of the asset. So for each asset we have to think which are the problems that can affect it, considering the CIA properties. So first we have to consider which is the final scope of the assets, it’s “motivation” for being in the system and it’s nature. It is not an easy task because it is not always known the chain of dependency between different assets in the company; that is because there is no a single person that knows the whole system in its integrity.
So in addition to stakeholders, additional information that comes from the field (logs of network traffic, activities running on top of the system and logs of the accesses, CPU and Memory usage patterns) must be used to better estimate possible incidents. Historical data has to be considered to trace previous incidents that has impacted one or more of the CIA properties to correlate the initial source of the problem (for example a bug) with the outcome of the incident (the system went down for hours).
This activity can be performed by using ML and bug data techniques to collect and correlate historical data.
3.2.3.2. Non-Malicious Vulnerability Identification
Once the incidents are identified, the vulnerabilities that caused the problem must be identified. This action is not trivial, commonly they aren’t technical vulnerabilities that can be identified with a vulnerability scanner, but they are error in the processes applied in the company. The ISO 27005 standard comes with a list of typical vulnerabilities related to non-malicious incidents.
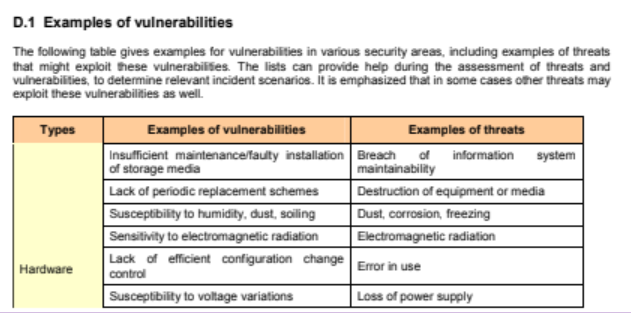
3.2.3.3. Non-Malicious Threat Identification
This activity is performed by answering the question:
Which unintended events may lead to the identified incidents due to the identified vulnerabilities, and how?
Considering that, in a cyber environment, there is a connection between the internal and external environment. There is no particular tool that can be used, it is a very context dependent task. Standard and best practices can be used; also in this steps the ISO 27005 and the NIST risk assessment guide can be used.
- ISO 27005 Annex C
It concerns the threat identification, like the previous case, the table is organized by typology of incident, and for each typology different threats are listed. The last column gives the possible sources of each threats: D, A and E; deliberate, accidental and environmental respectively.
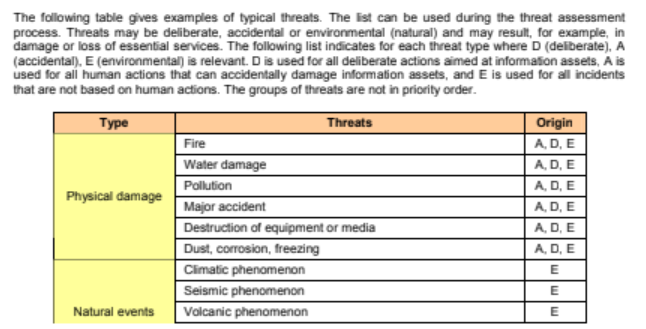
3.2.3.4. Non-Malicious Threat Source Identification
The last step consist in the identification of the possible threat sources, if we are not going to use the standards, to perform this step the question to answer is:
Who are the users of the system, and how can they cause the unintended or accidental events?
For example we can consider maintenance people, that can accidentally unplug a power cable; also in this case is possible to use information collected internally from incident happened in the past to try to prevent them.
3.2.4. Cyber-Risk Analysis
After the cyber-risk identification, the risk assessor has to perform the cyber-risk analysis. To project the risk into the risk matrix we have to identify its likelihood and impact. In the cyber-risk analysis there are some challenges. First of all there are two kind of risks: malicious and non:
- for malicious threats behind which there is human intent and motive, it can be hard to estimate the likelihood.
- for non-malicious threats the likelihood estimation can be performed by looking at historical data, and internally collected information.
From the point of view of the impact the kind of the risk does not influence the estimation. The last aspect of the cyber-risk analysis is to estimate if a technical problem can impact the business of the company. There is no a complete mapping between technical and business impact; to estimate the business impact the dependencies between different technical parts must be taken into account.
In this stage are produced two separate risk matrices: one for malicious risks, and one for the accidental risks; later in the process the two matrices will be combined.
3.2.5. Evaluation of Cyber-Risk
It is composed by four main steps:
- Consolidation of risk analysis. In a similar way to the general case, given a fixed risk we perform an estimation on it’s estimation uncertainties. Here we check if all the information available have been used, or if just an aggregation of the severity has been used.
- Evaluation of risk level. In this case, a review of the risk matrices is performed, so there is no particular thing to keep in mind.
- Risk Aggregation. We look for similarities between the incidents, the only difference from the general case is represented by the fact that in the cyber risk assessment we have two different risk matrices that in this step can be aggregate taken into account the different source.
- Risk Grouping, In the last step the risks are grouped based on the distinction between malicious and non-malicious cyber risk to improve the selection of treatments.
3.2.6. Treatment of Cyber-Risk
In the last step we decide how to treat each risk, ideally we want to manage all of them, but in reality, given the finite amount of resources and the presence of problems that can’t be fixed in practice, we have to prioritize and choose which risks accept.
In the cyber case there are two features that differentiate it from the general case, given the high technical nature of the possible problems:
- Sometimes applying a patch brings high indirect costs, in general socio-technical aspects and human involvement has to be considered.
- The distinction between malicious and non-malicious cyber-risks has the implications for the most adequate risk treatment. Sometimes the incidents can have a common solution, but in other cases this is not true. So different mitigation techniques must be put in place.
Working at the cyber-space does not mean to fix only technical problems, but also to act on the human-machine interaction side, via training for example. Many options exists, and all of them have to be considered. Another example is represented by possible vulnerabilities in the processes.
3.3. Monitoring and Review
It is the same as the General Case.
4. Common Repositories
There are a lot of public available data sources that provide information at different level of granularity. The problem is represented that the structure of those repository is not clearly present in any document.
4.1. MITRE CAPEC
MITRE is a publicly available catalogue of attack patterns along with a a comprehensive schema and a classification taxonomy created to assist in the building of secure software
It provides, semi structured information, on how an attack can be performed by an attacker, abstracting it from the single technique and vulnerabilities, but an overview of the steps of the attacks to consider. Mostly of the time this kind of information is used by the analyst during the Evaluation phase, by tester to perform penetration testing activities and for awareness purposes.


The document is not mapped 1:1 to the online repository. An interesting aspect of this repository is that it gives pointer to external repository that provide information which an high level of granularity.
The repository has a tree based structure, when exploring the repository we are presented by a view of the tree, depending on the view the links are arranged differently considering the criteria selected. The three views are: domain, mechanism and other.
- Targeted: fits perfectly
- Secondary: intermediate node.
The main problem of this repository is that it is full of plain text, from the human perspective is nice, but if we want to use this information to feed a semi-automatic system it is difficult: NLP is needed to correctly use the information provided.
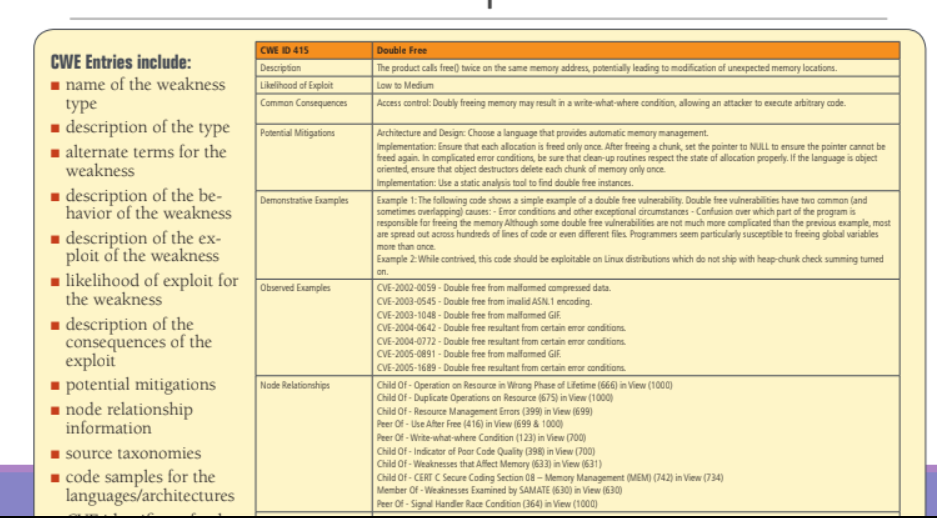
4.2. MITRE CWE
CWE is a community-developed list of common software security weaknesses. It serves as a common language, a measuring stick for software security tools, and as a baseline for weakness identification, mitigation, and prevention efforts.
It has the same structure of the CAPEC repository, some entries also include snippet of vulnerable code.
5. Vulnerability Classification NVD
Vulnerabilities may affect a system at different level: hardware, software, network, personnel, organizational. MITRE corporation maintains a list of disclosed vulnerabilities in a system called Common Vulnerabilities and Exposure.
There is a strong collaboration between MITRE and NIST. The dictionary is maintained by MITRE, that gives an unique identifier to the vulnerability, then it has to be analyzed, verified, and then published. When the vulnerability is in the dictionary it is taken has input by NIST. The naming convention is: CVE followed the number, the month of disclosure and the identification number. When published a vulnerability has different information attached:
- CVSS score
- Platform over which the vulnerability could be exploited
NVD database is one of the most structured source of information, it is useful because it can be imported into automatic analysis tools. Each entry has different section:
- Description
- Severity
- Solutions, and
- Possible tools
The problem of the last two sections is that the table of links does not differentiate which are the solutions.
The CPE tree, (Common Platform Enumeration) is composed by a set of strings that follows a strict structure: version:[h|a|o]:vendor:product:product_version:... all the other fields are optional. The same vulnerability can affect different configuration. The information can be used for fine tuning the likelihood evaluation of the single vulnerability.
The change history section can help to reconsider the likelihood score when analyzing a particular environment.
5.1. CVSS Score
The common vulnerability scoring system, captures the principal technical characteristics of software, hardware and firmware vulnerabilities.
It outputs a numerical score that ranges from 1 to 10, and tells how critical a vulnerability is. Each entry in the NVD database as a Base Score and a Vector. There are two version of the CVSS score, that consider a different set of attributes for evaluate the score. Today both scores are available for retro-compatibility reason.
CVSS is used to capture and quantify the severity of a vulnerability starting from its characteristics. The score gives an overview of the degree of problems that the exploit can cause inside the system. To assign a score the CVSS score use three categories of metrics:
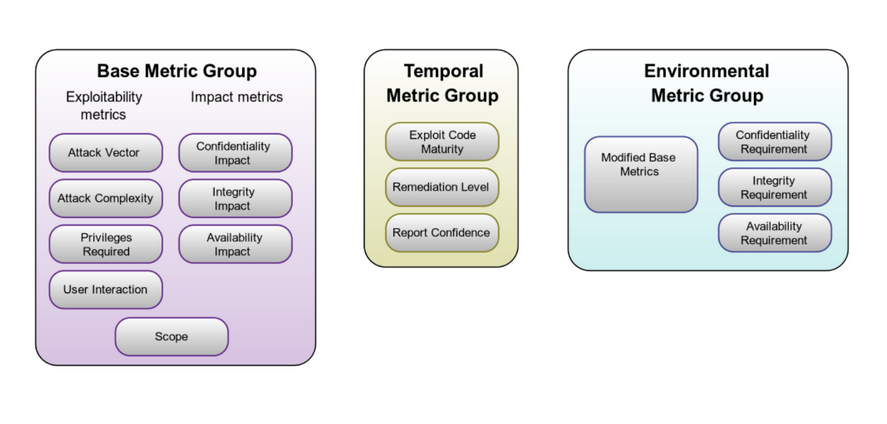
- Base metrics: the metrics inside this category regard intrinsic properties of the vulnerabilities. In this category there are two families of metrics: the exploitability metrics and the impact metrics.
- Exploitability metrics. The attack vector tells which kind of access is required to the machine to perform the attack, attack complexity has three discrete values (how much is difficult for the attacker to perform the exploit), privileges required is self explanatory, user interaction tells if the exploit can be performed with any kind of user interaction.
- Impact metrics. They regard the impact on the CIA properties. The last attribute: scope depends on whether the exploit of the vulnerability will change the type of control that the exploit has (like privilege escalation, or control of the physical machine).
- Temporal Metrics: they adjust the base metric of a vulnerability based on factor that change overtime. It has three attributes: exploit code maturity, Remediation level and Report confidence, they are not quantified inside NVD, but must quantified by the analyst.
- Environmental metrics: it is used to adjust the base metric considering the specific computing environment; taking into account the actors affected by the venerability, and the impact on the business flow of the company. It is composed by the: modified based metrics, and the CIA requirements that depends on the specific context.
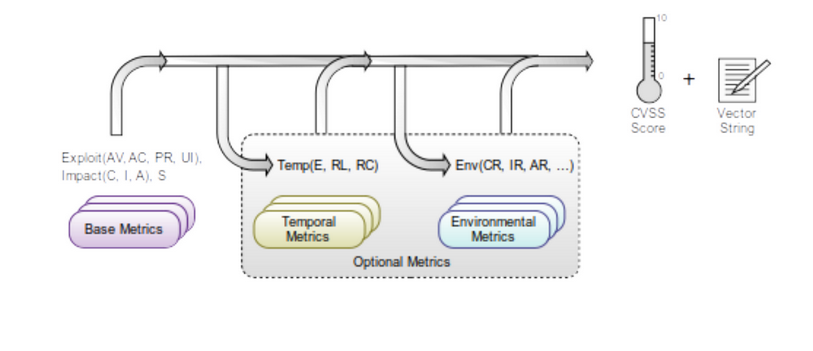
The vector can be used as a complementary information to the aggregated value. The CVSS is the most used score because it gives quantitative information that can be used to quantify the likelihood of an exploit.
So it starts by providing a generic assessment for each vulnerability, but it also provides to the analyst the capabilities to customize the severity of the vulnerabilities given temporal metrics and environmental metrics (customize it on the particular environment in which the vulnerability has been discovered).
5.2. CWSS Score
The common weakness scoring system provides a mechanism for prioritizing software weaknesses in a consistent, flexible and open manner.
It is similar to the CVSS, but it applied to weaknesses (so it applies to CWE). It is a collaborative, community-based effort that is addressing the needs of its stakeholders across government, academia and industry. The methodology provided can be applied to implement the control process (in this case to the risk management process). CVSS and CWSS can be leveraged together, because they give information at different level of granularity, the first is very detailed, the latter quantify an high level concept.
It produce a quantitative value that as a qualitative meaning; and it gives a common framework for prioritizing security errors (weakness) that are discovered. It’s structure is similar tu the CVSS:
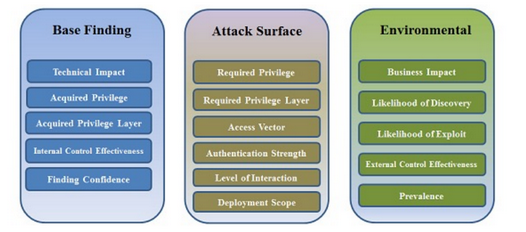
CWSS in organized into three metric groups: base findings, attack surface and environmental.
The base findings metric group captures the inherent risk of the weakness confidence in the accuracy of the finding, and strength of controls. The attack surface metric group regard the barriers that an attacker must overcome in order to exploit the weakness. The environmental metric group is the set of characteristics of the weakness that are specific to a particular environment or operational context.
The document provides the scale used to compute the score, and explain how to combine all the sub-scores to obtain the final one. The CWSS is not directly published with the weakness; it has been published last year, so it is evolving. The Base Findig sub-score range between 0 and 100, while the attack surface and environmental metrics sub-scores ranges between 0 and 1; The final result ranges between 0 and 100.