Incident Management
Table of Contents
- 1. Lecture 18
- 2. Incident Management
- 3. Incident Management Process
- 3.1. Incident Handling Life cycle
- 3.1.1. Preparation
- 3.1.2. Detection and Analysis
- 3.1.3. Incident Analysis
- 3.1.4. Incident Documentation
- 3.1.5. Incident Prioritization
- 3.1.6. Incident Notification
- 3.1.7. Containment Strategy
- 3.1.8. Evidence gathering and handling
- 3.1.9. Identify Attacking Hosts
- 3.1.10. Eradication and Recovery
- 3.1.11. Lesson Learned
- 3.1. Incident Handling Life cycle
1. Lecture 18
- Class: Security Governance
- Topic: Incident management
- Reference: NIST SP 800-61
2. Incident Management
The incident management process is one of the most important processes inside an organization. Due to the fact that ICT domain is full of uncertainty due to missing pieces of information, and that some vulnerabilities are unknown (zero day, few details, etc) something bag can happen. For this reason it is important to be prepared to mitigate and react to a possible incident.
The incident management process, is the process to design and develop in order to manage possible incidents that may occur. Timeliness is a crucial factor, more you are ready to respond to an incident the less trouble the attacker may create.
An Incident is an event that could lead to loss of, disruption to, an organization’s operations, services or functions.
So an incident reduces the capability of an organization to complete it’s business goals.
Incident management is the process aimed at identify, analyses and correct hazards to prevent a future re-occurrence.
Analyses what the attacker is trying to do, and estimate how much dangerous will be the attack to put in place protection measures that will contain and mitigate the attack consequences. A good incident management system will give an alert when the attack start and also give information about how to mitigate it.
In order to respond quickly the process as to be designed:
- Train people
- Prepare the material to use to manage the incident
- Procedures already defined to enable communications between the people who handle the incident
- Role and responsibilities well defined
This process must be done in advance. If we are not able to design such a process we’ll not be able to respond quickly to an incident, giving the attacker the possibility to create damages to the organization business. Having a process that is not implemented efficiently will result in a loss of money.
2.1. Cybersecurity Incident
Any malicious (or suspicious) act that: compromises the electronic security perimeter or physical security perimeter of a critical cyber asset, or the disrupts the operation of a critical cyber asset.
We have to consider not only the physical intrusion, but also the possibility to cause harm, so we have to be worried also for suspicious events, and we have to correlate data and alert to correctly identify the starting point of an incident.
Compromission is an action that will harm integrity and confidentiality of the asset, disruption is more related to the availability of the system itself.
An incident is the act of violating an explicit or implied security policy. These include: attempts to gain unauthorized access to a system or its data; unwanted disruption or denial of service; the unauthorized use of system for the processing, or storage, of data (integrity compromission); changes to the system (hardware or software) without the owner’s knowledge, instruction, or consent.
The compromission of integrity can be numerous and each of them must be observed to implement a good incident management process.
An incident is the act of violating an explicit or implied security policy (according to NIST Special Publication 800-61). These include but are not limited to:
- attempts (either failed or successful) to gain unauthorized access to a system or its
data
- unwanted disruption or denial of service
- the unauthorized use of a system for the processing or storage of data
- changes to system hardware, firmware, or software characteristics without the owner’s knowledge, instruction, or consent.
3. Incident Management Process
The incident management process is composed by two macro parts: the prevent process, that goal is to prevent an incident to happen; and the contain process, that, when an incident will happen, contains all the activities that helps us to resolve the incident as fast as possible.
The incident management serves the primary process and the organization as whole.
The incident management is composed by different sub-tasks; some are related to a design phase, and others are related to the run-time process. Of course we try to patch most of the vulnerabilities before that the occurrence of an incident. The phases are:
- Vulnerability Handling
- Artifact Handling
- Announcement. It is the part of the process related to the awareness: how to deal with the share of knowledge and the forensics aspect of the incident.
- Alerts. Parts of the system needed in order to observe the IT infrastructure at run time to identify signs of possible attacks, and a logging platform to identify casual-effect relationships about an incident.
- Other IM Services. Accessory services that will provide additional information and procedures.
- Incident Handling. How we should behave when an incident occurs.
Each activity can be divided in other sub-activities; for example Incident handling can be decomposed in: reporting and detection, triage, analysis, and incident response. This process is a loop because additional information can be acquired later, or some countermeasures can be put in place, leading to another loop to further contain the attack. It is fundamental to re-assess and re-evaluate an incident to manage it correctly.
3.1. Incident Handling Life cycle
The loop itself is the online management of the incident, but it is part of the whole process. Some preparation activities must be done, and also post-incident activities must be performed to review the procedures and the process itself to understand what didn’t work and which are the lesson learned. The post-incident activity is also useful to improve the incident handling life cycle.
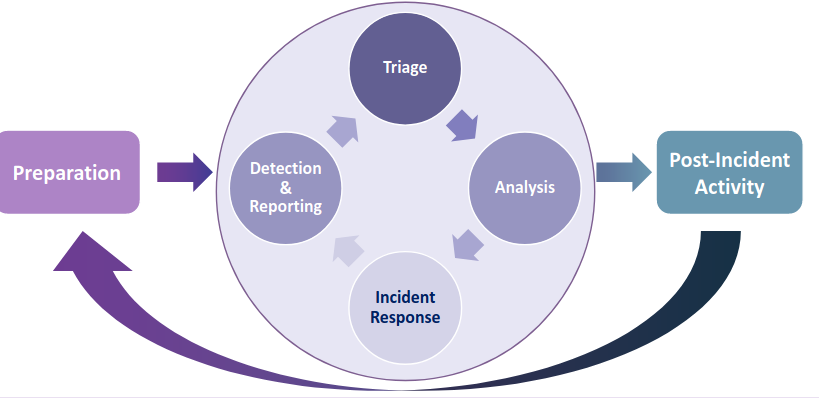
3.1.1. Preparation
Before the incident happens, we have to define how we want to behave in case of incident. We have to be fast and accurate to mitigate the incident. Awareness is fundamental in this phase:
- Identify important assets
- Perform a good prioritization
- Context awareness
The preparation is split in two sub phases: Preparation to incident handling and Prevention of the incident.
3.1.1.1. Preventing: handling incidents
In this phase, we need to perform several basic tasks: spending time on preparing the communication procedures and facilities needed to solve an incident. When the incident will occur, time is fundamental, so it is important to know: what to do, and who contact.
The material to be prepared could be for example smartphones or storage facilities to use to communicate easily over the system. Then a toolbox must be ready: it is composed by all the hardware and software needed to perform analysis; it could include:
- Forensics workstations
- Removable media (in order to copy data from devices and collect evidences)
- Laptops for logging the steps of the process and document all the steps.
- Template of the document to fill. A structured format is useful to know what to consider and investigate without spending time to think.
- Cryptographic hashes to digitally sign the information copied to ensure that the evidence collected are not altered by the analysis.
- List of critical assets, to be sure that all the important things were considered.
- Mitigation software like clean OS application for restoration (backups).
Practically speaking many incident response team create a jump kit: a portable case that contains all the materials needed during an investigation. The purpose of having a jump kit is to facilitate faster responses.
Given that the machine under attack is isolated from the network, hardware for direct access is used to create a LAN in which the machine under attack and the analysis machine belong.
3.1.1.2. Preventing: incidents
In this phase we’ll try to prevent the incident to happen, reducing as much as possible the likelihood of the incident. In this case we work on both the technical side, and the human side. Implement and design procedures and processes in order to prevent the incident to happen; form this point of view the prevention means prepare the procedure and workflows to follow when an incident happens; beside that other activities to perform are:
- Risk assessment
- Host security. Manage the hosts according to best practices of network and host security
- Network security
- Malware prevention
- User awareness and training. Most of the time incidents happen because the human is the enabling factor.
3.1.2. Detection and Analysis
We have to observe the system to try to identify if something bad is happening. This phase has the aim to raise an alarm as soon as possible something bad is identified. Try to avoid a ticket for every suspicious alert, for example when a security assessment is going on the IDS will raise alarms, so it is important to be sensible on what alarms to consider.
A mechanism is needed in order to define when we should open a ticket and call the incident response team.
3.1.2.1. Attack vectors
The most common attack vectors that every company should be ready to handle are:
- external/removable media
- Attrition (i.e. brute force attacks). For example the rate at which login request are happening. The same happens for a DoS attack, or the usage of the network (peaks during work days, but less data during night or weekends).
- Web
- Emails. Employees are not trained, so it is a common phishing vector: the user will not check carefully the link or the attachment.
- Impersonation
- Improper usage
- Loss or theft of equipment
3.1.2.2. Signs of an Incident
Once we identify the most common attack vector to consider, we have to look to the potential signs, we know where to look, now we have to know what to look for.
We can try to identify a deviation for a normal behavior (may cause false positives), or try to look for specific pattern of actions (may lead to false negatives). Other challenges of this phase are represented by an huge volume of information generated by a network with a a lot of devices, multiple servers, access points, and smartphones.
Also the analyst must be capable to discern what is really an incident or a normal, but rare, behavior of the system; of course this is not an easy task.
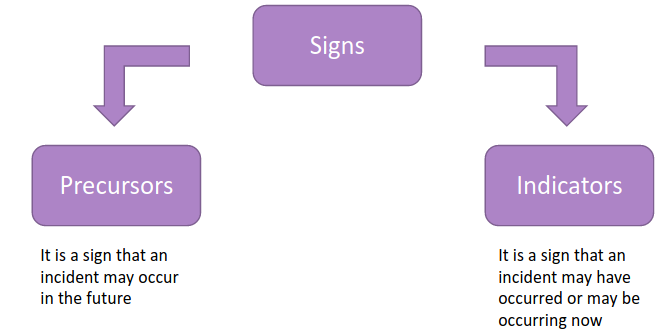
Different approaches may be used to perform a good sign identification. We can observer a precursor of an incident and the indicators if an incident. The Precursor are really difficult to identify, even after a forensics phase.
Indicators are the sign that something bad is happening, they are the output produced by the IDS (or SIEM). A lack of experience may lead to a bad correlation between indicators and the classification of the incident, underestimating it. There exist new technologies that can be used to achieve better identification of indicators.
Common sources of Precursor and Indicators are:
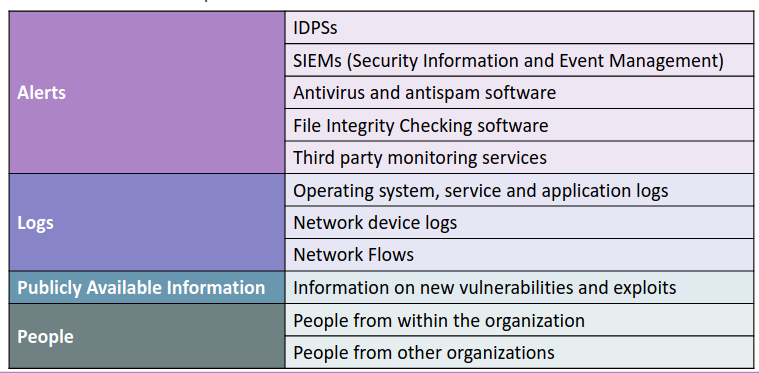
There is a trade off between monitoring capabilities and performance of the system. For example HIDS are used only on particular hosts and for a limited time.
3.1.3. Incident Analysis
Once we collected info from our data sources we can classify which is the concrete pattern of the incident, and assign a priority to it. Few issues are present during this phase: in practice it is difficult to perform an accurate analysis when the data used at the source may be inaccurate.
The inaccuracy is present because there can be:
- Accuracy loss (false positives/negatives)
- Huge amounts of alerts to analyze.
- Zero-day vulnerabilities
- Indicators that follows from different root causes
- Many incidents are not associated with clear symptoms.
For this reason the incident response time has to be composed by highly experienced and proficient staff capable to analyze precursors and indicators effectively and efficiently.
Some recommendations are:
- Profile network and systems
- Understand normal behaviors
- Create a log retention policy
- Perform Event Correlation
- Keep all hosts clocks synchronized (important for cause-event correlation)
- Maintain and use a knowledge base
- Research
- Run packet sniffers to collect additional data, interesting information about interaction patterns can be extracted in this way.
- Filter data
- Seek assistance
3.1.4. Incident Documentation
In all of the above ten activities, there are many data and different content to consider, starting from analyzing the logs, the network traces, and the pattern inferred from the logs and shared from the community.
There is a big effort in the documentation part of the process, the documentation will help the analyst to understand what went wrong:
- identify causal effect relationships
- root cause of the incident
- perform correlation
The fundamental action is to recontact the timeline, this is really difficult if the clocks of the hosts are not synchronized. It seems trivial, but practically speaking it is not, because there may be different events happening concurrently, making difficult the establishment of causality relationships between those events.
Of course in doing this documentation, we need to rely on different tools. The main tools used are ticketing services, they are like logger of activities (the ISO 5K standard tells which are the main activities to perform and which are the info that must be present in the logs). We have to log not only the event itself, bust also how the incident has been managed.
Finally, we have to consider that if the information are logged, the attacker will try to hide his traces from the system, so he’d delete logs, or tamper them. For this reason the logs must be private, and not accessible by everybody.
Review the logs of the process and then compare it to the guidelines of the ISO standard, to highlight deviations and mistakes done by the analyst.
3.1.5. Incident Prioritization
The prioritization must keep in mind the business perspective, so it is fundamental to fix as fast as possible the incidents that will impact the business part of the company. There are mainly three factor to consider:
- The functional impact of the incident.
- The impact over the information. Data consumed by the organization.
- How much does it cost to recover from the incident. This notion is similar to what discussed during the risk management, in that case to reduce the residual risk, but now we prioritize in the short terms.
Recoverability is a factor that will drive the cost: more time to recover from an incident, more prioritize has the incident. Of course prioritizing is not easy. For managing correctly the incident management process we need a good degree of situational awareness, and tools able to take decision in an informed way. Take good decision under pressure.
Despite the time, and possible cost of the incident, there is also the need of someone that take care of the incident, so also the competence of the people that take care of the incident is a driving factor on the prioritization decision.
3.1.5.1. Example
| Category | Definition |
|---|---|
| None | No Effect to the organization’s ability to provide services. |
| Low | Minimal effect; we can still provide critical services, while loosing some kind of capabilities |
| Medium | Provide just a subset of critical activities. |
| High | No longer able to provide critical services |
In this case we are looking at the impact at the short term.
3.1.5.2. Example. Information Impact
| Category | Description | |
|---|---|---|
| None | No CIA | |
| Privacy Breach | Services available, but confidentiality property infringed | |
| Proprietary Breach | Unclassified proprietary information. Increase on the level of quality of the information compromised | |
| Integrity Loss | Sensitive Info was deleted or changed |
3.1.5.3. Example Recoverability Effort
How to classify the cost of the recoverability.
| Category | Description |
|---|---|
| Regular | Time to recovery is predictable with existing resources |
| Supplemented | Time to recovery is predictable with additional resources |
| Extended | Time to recover is unpredictable, additional resources or external help is needed |
| Not Recoverable | Recovery from the incident is not possible, for example when personal information has been disclosed. The information may be improved. (Non piangere sul latte versato) |
3.1.6. Incident Notification
The notification of the incident is strictly related to the part done in the preparation phase in which the people to be contacted are listed. Having a good notification process is fundamental to progress to a fast incident management process.
When dealing with this aspect, two main points must be considered: roles and responsibilities, in order to create a notification list to know who must be contacted and in which way. Somewhere the communication procedures are policies must be defined. Another criteria that should be kept in mind is related to the fault tolerance aspect:
- Being centralized, we have a central point of failure
At the same way, it is not possible to rely on a single person for all the tasks, so multiple lists of role e responsibilities must be defined, maybe prioritizing them, to be fault tolerant.
3.1.7. Containment Strategy
As in the risk estimation we have to minimize as much as possible the impact due to mitigation, the containment measure should not generate additional costs for the organization. For this reason organizations should define acceptable risks in dealing with incidents and develop strategies accordingly.
Common mitigation strategies are switch off (best strategy in case of no critical service), disconnect the system from the internal network, or disable some functionalities (reduce the capabilities of the attacker). We need to reason on the trade-off containment/progress of the attack: the matrix used is the risk.
Containment strategies are incident dependent, solutions can’t be identified a priori, but it is possible to determine a general category of incident, and define general containment strategies, or guide the creation of containment strategies based on the asset.
Other guidelines are represented by the potential damage to the asset, the need of collecting evidences, consider the availability of the service (from the business perspective), time and resources needed to implement the mitigation and it’s effectiveness (temporary solution or final solution), and the duration of the solution.
3.1.8. Evidence gathering and handling
The evidence gathering and handling has two main purposes: to resolve the incident and oblige to legal regulations. In such cases, it is important to clearly document how all evidence (including compromised systems) has been preserved. The attacker will try to hide himself, preventing the defender to gather evidences.
This aspect seems a collateral aspect, but it is not, so it must be kept into account during the process, because is not just a technical issue, but more.
3.1.9. Identify Attacking Hosts
We would like to understand where everything started, from the first action performed by the attacker, till the end. Ideally this is the target of the analyst, practically speaking this is not always possible because most of the time the attacker knows techniques to cloak himself.
There are not golden bullets, but there are some techniques:
- implementing whitelisting (blacklisting)
- research the attacking host through search engine (useful to identify phishing campaigns, and well known APTs)
- use incident databases (one of the main interaction between organization and external entities)
- monitor the communications, trying to identify communication patterns (Trojan, C&C, data ex-filtration).
Again those techniques, will not guarantee the safety of the system, but are helpful to identify the presence of an attack.
3.1.10. Eradication and Recovery
Eradication, means taking the attacker out of the system, so we have to make sure that the system is clear, and that he has not any opportunity to cause damage. It is based on the physical removal of the infected components, and their restoration.
Also it consists in the removal of breached user accounts, and via the identification and patching of all vulnerabilities exploited.
In the recovery,the analyst will restore the functionalities at the stage at which there were provided before the attack; restoring the system to normal operation, also we have to confirm that the system are functioning normally.
A recovery stage may involve:
- restoring from clean backups. (Useful for integrity breach)
- rebuilding the system from scratch. (Extreme recovery solution, it requires time, effort and money)
- replace compromised files with clean version. (Similar to the backup)
- installing patches.
- changing passwords
- hardening of network perimeter security. (Close open ports that are not needed, firewall rules, boundary router ACL)
3.1.11. Lesson Learned
When the incident is resolved, we have to learn from our mistakes, so we have to understand if the issued comes from the organization, or from lack of information (due for zero-day vulnerability, or unknown attack paths), and simply need to avoid that the same attack happens in the future.
Question to be answered are:
- Exactly what happened, at at which time?
- How well did staff and management perform in dealing with the incident? Where the procedures followed? Where they adequate? (Here the answer is important: if the fault was due to a lack of adequate procedures we can do better, on the other hand the attacker was greater than the security team) Reduce as much as possible the possibility to loose against a competitor of the same level.
- What information was needed sooner? (having the right information at the right time is fundamental, if we need to spend time to find the information needed, the management of the issue will be done slowly. Was the lists of vulnerabilities available?)
- Where any sets or actions taken the might have inhibited the recovery? (The recovery of the system must be fast, from the point of view of the incident management, recovery plans must be identified a priori, if the option is ready at the beginning it is easier to take a fast decision)
- What would do the staff and the management do differently the next time a similar incident occurs? (Understand if it is a problem of the team, or a problem of the procedures.)
- Which are the corrective actions can prevent similar incidents?
- What precursor indicators must be watched for in the future to detect similar incidents? (Can be used to create new monitoring rules, to raise an alarm early enough)
- What additional tools of resources are needed to detect, analyze, and mitigate future incidents? (Maybe the problem is that the team is not working with the right tools)
Most of the time incidents are related due to lack of awareness on the technologies and procedures, awareness should be improved inside the company.